Spot Workshop > Spot Ocean for Spark Workshop > Ocean spark Workshop > Application Workflows > Launching a notebook
Launching a notebook
For this next part we are going to run a jupyter notebook connected to the ocean for spark cluster in order to do this we need to run this line of code
jupyter notebook \
--GatewayClient.url=https://api.spotinst.io/ocean/spark/cluster/<your ocean spark cluster id>/notebook/ \
--GatewayClient.auth_token=<spot token> \
--GatewayClient.request_timeout=600
- The GatewayClient.url points to an Ocean Spark cluster, with an Ocean Spark cluster ID of the format osc-xxxxxxxx that you can find on the Clusters list in the Spot console.
- The GatewayClient.auth_token is a Spot API token.
- The GatewayClient.request_timeout parameter specifies the maximum amount of time Jupyter will wait until the Spark driver starts.
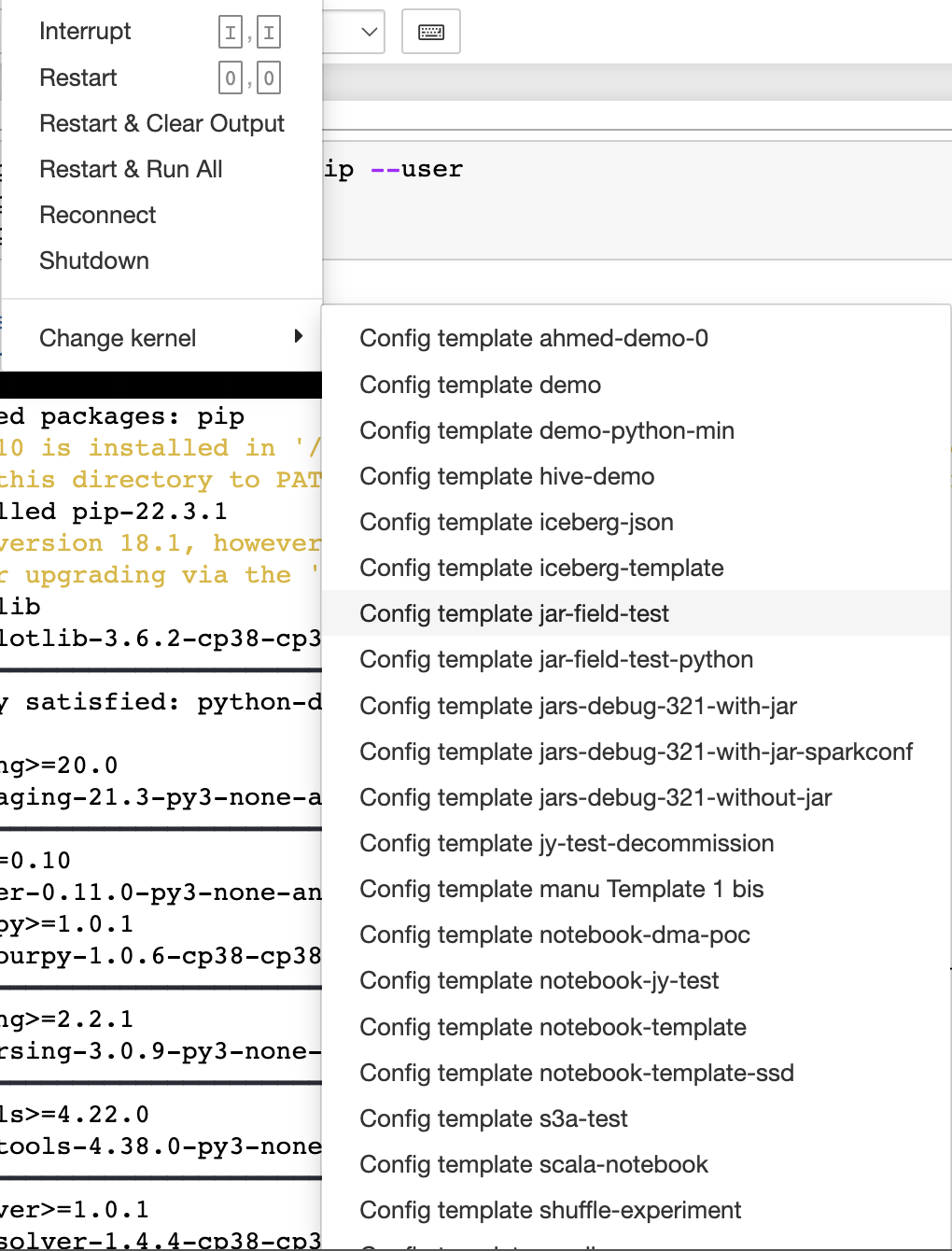
once this is done you will find that the kernel to execute is ready as shown in the image below

The list of kernels that exists in the ui here is the list of the configuration templates that we configured in the ocean for spark console
Once you are finished with the notebook and it’s time to close it you should not use the “Kill” action from the Spot console, because Jupyter interprets this as a kernel failure and will automatically restart your kernel, causing a new notebook application to appear.
You should close your notebooks from Jupyter (File > Close & Halt). This will terminate the Spark app in the Ocean Spark cluster.